|
To use Sitetree in your application you must know how it works.
The following sequence diagram shows what is going on:
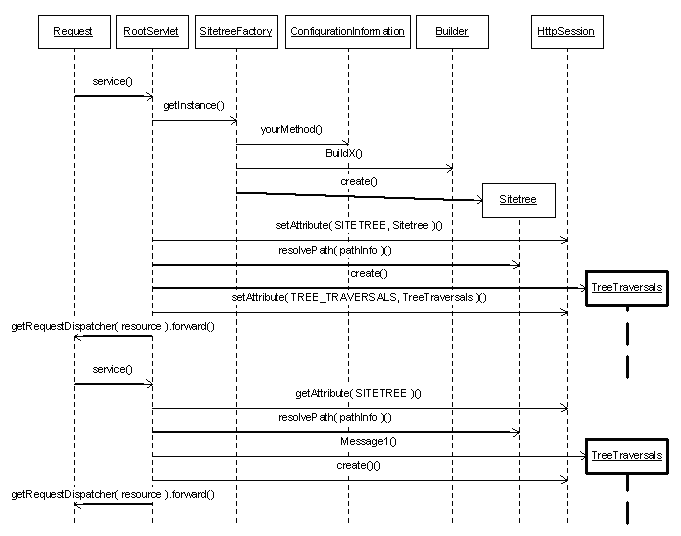
What happens is this:
- The first request for a particular session is received by the
RootServlet:
it examines the session and finds no
Sitetree
on it.
- It calls the
getInstance() method on the
SitetreeFactory
class that it was configured to use. This is the class you write.
- SitetreeFactory examines the request and session and determines which Sitetree to return for it.
- The factory gets a string representation of the desired tree passes the string
to one of the static methods on
Builder.
This creates a new tree that is returned to the RootServlet
- The RootServlet attaches the new Sitetree object to the session and uses it to
resolve the incoming request to a resource.
- The resolved information is encapsulated in a
TreeTraversals
object and attached to the request.
This object holds all information for downstream resources so that it is not affected by
other requests that may arrive for this session while this one is being processed.
The information is stored in various TreeTraversal objects.
These objects show different views, or traversals of the Sitetree.
For example the left nav, tabs (nodes that are direct children of the
root on the tree), a path to the current node in focus, etc.
There are a number of TreeTraversal implementations included in the package and
you can create your own.
See the
TreeTraversal
abstract class for more information.
- RootServlet dispatches (forwards) the request to the resource indicated by the resolved location.
- Later requests do not create a new Sitetree, they just have to retrieve the Sitetree
from the request and use it in the same way as described above.
This is the standard way to use Sitetree - other possibilities exist.
However the usage of RootServlet (or a Servlet like it) makes it very easy to code most of the logic
in a single class.
The string representation of the Sitetree must follow the grammar defined by
Builder.
Here is an expression in that grammar:
home "Home" / [
index.rs /home.jsp
noAccess.rs /noAccess.jsp
badSite.rs /badSite.html
]
whatsNew "What's New" / [
index.rs /whatsNew/index.jsp
] {
mediaCentre "Media Centre" [ jsp.rs /whatsNew/mediaCentre.jsp ]
corpEvents "Corporate Events" [ jsp.rs /whatsNew/corporateEvents.jsp ]
education "Education" [ jsp.rs /whatsNew/education.jsp ]
}
This expression has two
TreeComponents
separated by white space: 'home' and 'whatsNew'.
The first component is named "home".
This name will be used in the URL to navigate to that component.
The component has only one node that is it's root node.
It's display name ("Home") is used as a label for the user to see in the nav bar.
The third token is the path that this component should be connected to in the sitetree.
In this case it is '/', or directly to the root.
The three lines within the [...] braces define locations of this node.
This means that the following URLs will be dispatched as:
| |
/home/index.rs |
--> |
/home.jsp |
| |
/home/noAccess.rs |
--> |
/noAccess.jsp |
| |
/home/badSite.rs |
--> |
/badSite.html |
It also means that if the user clicks on the "Home" link they will go to the primary (first)
location: /home/index.rs.
The second component is named "whatsNew".
It has a single location with the URL /whatsNew/index.rs
It also has 3 child nodes: "mediaCentre", "corpEvents", and "education".
These nodes will appear as distinct nodes to the user in the nav bar.
For example the URL /whatsNew/mediaCentre/jsp.rs will be directed to the resource
/whatsNew/mediaCentre.jsp
A formal definition of the grammar can be found
here.
One of the things you have to decide on to use the Sitetree is how it will be deployed.
We highly recommend that you use the
RootServlet
or some extention of it.
This is how it works:
- You decide an extension to use for URLs that will be controlled by the Sitetree.
Let's say this is ".rs" (as in the example).
This must not be any extension that you are going to use for your resources.
- Configure your servlet container/web server to direct all requests of that extension
to the
RootServlet. For example:
<servlet-mapping>
<servlet-name>RootServlet</servlet-name>
<url-pattern>*.rs</url-pattern>
</servlet-mapping>
- Ensure all the locations coded into your Sitetree end in ".rs".
- Ensure all the resources coded into your Sitetree end in an extension that is handled
properly by the container. For example a resource ending in ".jsp" should go to a JSP page.
In the example
provided we are assuming that the servlet container automatically maps ".jsp" extensions
to a module that handles JSP requests.
- What will now happen is that the request will go to the
RootServlet first
(because it has an ".rs" extension). RootServlet will forward it
on to the resource indicated via the container.
- This should make your site work. To increase security you will want to block the
resource URLs from access by the public. You do this by configuring your web server
so that any requests for resources directly (e.g. "*.jsp") are not passed onto
the servlet container.
Here are some other notes for using Sitetree:
- You can do more advanced things with the string representation of tree components:
- Mark a resource as
secure.
This will only allow a request to that resource
if the request uses the
https protocol.
- Mark a node as
invisible.
TreeTraversal
objects will not record an
invisible node and hence users will not see it in the nav bar.
This is useful to put structure into URLs that you want to be able to serve
but do not what to show on the nav bar.
- By default tree components are added to their parent as the last child.
In the above example "Home" will appear first because it was added first.
You can change this behavour by defining the
childPosition
attribute.
- The
loadOrder
attribute can provide further control over the
construction of tree components.
Components with lower
loadOrder numbers are attached to the Sitetree first.
You will need this if you have a component that attaches to another component
rather then directly to the root.
See the
grammar
specification more information about how to set these properties.
- The Sitetree object is attached to the session and is not thread-safe.
Hence any access to it should synchronize on the Sitetree object itself.
In reality you should never have to do this.
You should always use the
TreeTraversals
object instead.
This retrieves and caches information in a thread-safe manner.
- A number of
TreeTraversal
implementations are provided.
These should cover any views of Sitetree that you would normally want to show the user.
If you require a specialised view you can extend the TreeTraversal class to provide
one.
- The implementation of
SitetreeFactory
provided -
SimpleSitetreeFactory
- parses the
entire Sitetree from a single string.
You will need to extend this to provide functionlaity for more complicated sites.
They standard way of doing this is to generate multiple
TreeComponents
and build the Sitetree based on the information on the request (or session).
For example, when someone logs on, you can determine that they require sections A, B,
and D of your site, but not section C.
So you retrieve these sections (as Sitetree components), add them to a new Sitetree,
and return it.
- Sitetree and all it's contained objects have a clone() method.
The clone() method is useful to create a deep copy of the object, it avoids having to go back
to persistent storage to create a new one.
This is useful in the implentation of the SitetreeFactory object to create a copy of a Sitetree
or a TreeComponent that you already have.
|